The introduction of the General Data Protection Regulation (GDPR) in Europe in 2018 sent shockwaves through the global data ecosystem. Affecting over 28 million businesses worldwide, it marked a watershed moment in how organisations handle Personally Identifiable Information (PII). Data protection regulations, often referred to as privacy laws, have since become a defining trend, as real-world data becomes increasingly regulated. These laws mandate businesses to protect customer data and ensure its use complies with stringent privacy standards.
Before 2018, privacy was largely a legal “check-the-box” exercise. Today, it has evolved into a technical challenge. With over 130 countries now enforcing privacy laws, businesses must ask themselves: How can they meet these legal and technical requirements without stifling innovation?
The role of privacy technologies
Privacy laws impose both legal and technical obligations on businesses. While legal teams can navigate compliance aspects, the technical challenges require robust privacy engineering solutions. Privacy technologies address these challenges by determining where and how to add “noise” to data. The three key methods are:
1.Data anonymisation: This method involves information sanitisation through techniques like suppression, pseudonymisation, generalisation, swapping, or perturbation to remove personal identifiers. In other words, this method destroys information to protect privacy.
Benefits:
- Ensures privacy through de-identification.
- Easy to implement for structured datasets.
Difficulties:
- Vulnerable to re-identification risks (e.g., gender, ZIP code, and date of birth can identify 87% of people globally).
- Greatly reduces data utility based on the extent of anonymisation.
2.Data encryption: This method secures data by converting it into ciphertext using mechanisms like Public Key Infrastructure (PKI), Homomorphic Encryption (HE), Secure Multi-Party Computation (SMPC), Zero-Knowledge Proofs (ZKP), and Private Set Intersection (PSI).
Benefits:
- Strong protection against unauthorised access.
- Compliant with most data protection laws.
Difficulties:
Key management complexity, risk of key collisions, and potential data breaches.
Data utility is significantly diminished, limiting its usability for analytics.
3.Synthetic data: Synthetic data: This method generates artificial data using generative models like Generative Adversarial Networks (GANs), Diffusion Models, and Language Models (LMs), without any direct link to real-world data.
Benefits:
- Provides high data utility while maintaining strong privacy.
- Enables quick data sharing for model training and software testing.
Difficulties:
- Potential risks of overfitting or generating outliers.
- Requires advanced data expertise and computing resources.

The three pillars of AI development
To understand the role of synthetic data, we must consider the three foundational pillars of AI development: compute, algorithm, and data.
- Compute: The infrastructure that powers AI, led by NVIDIA (GPUs), Google (TPUs), and AWS (cloud computing).
- Algorithm: Advanced models developed by pioneers like OpenAI (transformers), DeepMind (reinforcement learning), and Meta (large-scale language models).
- Data: The lifeblood of AI systems, increasingly becoming a scarce and highly regulated resource.
The data bottleneck
Real data is limited, valuable, and increasingly difficult to use due to three main challenges:
- Privacy risks: Customer data is laden with sensitive information.
- Intellectual Property (IP): Publicly available data cannot always be commercialised.
- Data scarcity: High-quality data for AI/ML is finite, with studies projecting its exhaustion for training purposes between 2026 and 2032.

The 2024 AI Index Report by Stanford University underscores this challenge, predicting that high-quality language data could be depleted by 2024, low-quality language data within two decades, and image data by the late 2030s. The demand for training datasets is expected to grow exponentially, with Epoch AI estimating a need for 80,000x more data by 2030 to scale AI models effectively.
Synthetic data: A transformative solution
Synthetic data is emerging as the key to overcoming data scarcity, privacy, and IP barriers. By generating artificial datasets that mimic real-world characteristics, synthetic data allows businesses to:
- Ensure privacy: Anonymises data while maintaining compliance with global regulations.
- Protect IP: Produces proprietary datasets without relying on publicly available data.
- Overcome scarcity: Simulates diverse and high-quality datasets for AI/ML applications.
Unlike real-world data, synthetic data is scalable, diverse, and customisable, making it a game-changer for AI/ML development.
The future of AI will be built on foundations of privacy
As the UK Financial Conduct Authority notes, synthetic data is not bound by data protection obligations like GDPR as long as it does not link to identifiable individuals. This positions synthetic data as the cornerstone of a privacy-preserving, innovation-driven AI ecosystem.
In an era where data is the new IP, businesses must embrace synthetic data to fuel AI advancements responsibly. By addressing privacy risks, regulatory compliance, and data scarcity, synthetic data ensures that better data equals better AI, paving the way for a more sustainable and ethical innovation in AI development.
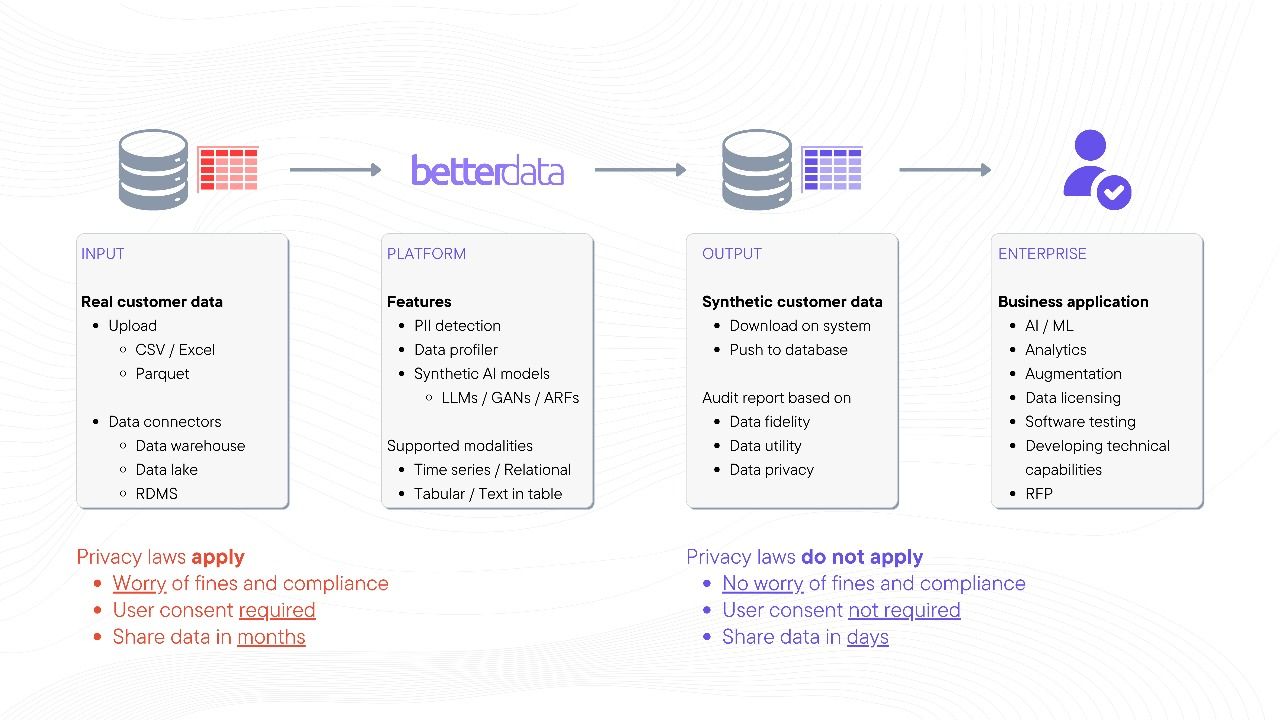
Check out the reference below to see when and where synthetic data can be applied.



![Read more about the article [Weekly funding roundup] Venture investments get a leg-up from unicorns](https://blog.digitalsevaa.com/wp-content/uploads/2021/02/Weeklyimage-1577460362436-300x150.png)





